
Audio-visual synchronisation requires a model to relate changes in the visual and audio streams. Prior work focused primarily on the synchronisation of talking head videos (left). In contrast, open-domain videos often have a small visual indication, i.e. sparse in space (right). Moreover, cues may be intermittent and scattered, i.e. sparse across time, e.g. a lion only roars once during a video clip.
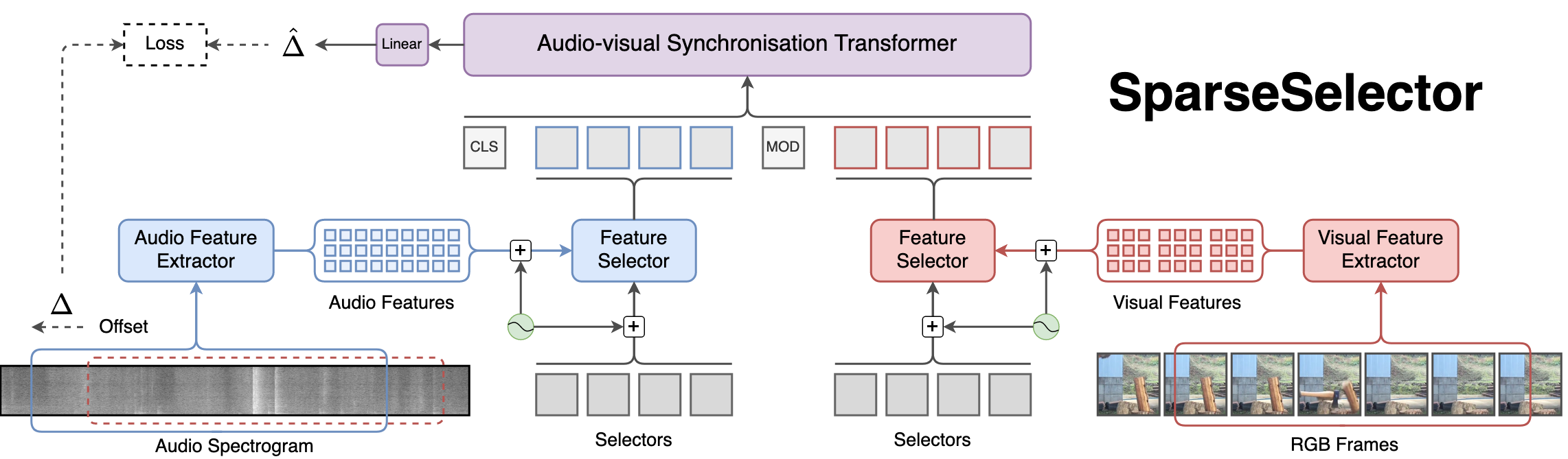
It is well-known that transformers have flattered many areas of deep learning including video understanding. Despite reaching the state-of-the-art in many tasks, it scales quadratically with input length. Moreover, the fine-grained audio-visual synchronisation of videos with sparse cues requires higher frame rate, resolution, and duration. To this end, we propose SparseSelector, a transformer-based architecture that enables the processing of long videos with linear complexity with respect to the duration of a video clip. It achieves this by 'compressing' the audio and visual input tokens into two small sets of learnable selectors. These selectors form an input to a transformer which predicts the temporal offset between the audio and visual streams.
Opposed to a dense in time and space dataset (e.g. cropped talking faces as in LRS3), we are interested in solving synchronisation on sparse in time and space videos. Due to its challenging nature, a public benchmark to measure progress has not yet been established. To bridge this gap, we curate a subset of VGGSound of videos with audio-visual correspondence that is sparse in time and space. We call it VGGSound-Sparse. It consists of 6.5k videos and spans 12 'sparse' classes such as dog barking, chopping wood, skateboarding, etc.
Download annotations: vggsound_sparse.csv








In addition to the VGGSound-Sparse dataset, we encourage benchmarking future models on
videos from LRS3 dataset without the tight face crop or, as we refer to it,
dense in time but sparse in space.
The shift from the cropped setting to uncropped one is motivated by the following two arguments:
1) The LRS3 dataset can be considered to be 'solved' as models reach 95%
performance and above with as few as 11 RGB frames;
2) The videos that are officially distributed are encoded in
MPEG-4 Part 2, a codec with a strict
I-frame temporal locations which might encourage a model to learn a shortcut rather than
semantic audio-visual correspondence (see later sections and the paper for details).
In this project, we retrieve the original videos of LRS3 from YouTube and call this variation LRS3-H.264 ('No Face Crop'). Furthermore, these videos are encoded with the H.264 video codec which has a more complicated frame-prediction algorithm compared to the MPEG-4 Pt. 2 which makes it hard for a model to learn a 'shortcut'. Note, simply transcoding from MPEG-4 Pt. 2 to H.264 does not solve the issue.
| LRS3 ('No Face Crop') | VGGSound-Sparse | |
|---|---|---|
|
21 offset classes from –2.0 to +2.0 sec with 0.2-sec step size.
The metric tolerates ±1 temporal class (±0.2 sec) mistakes.
Accuracy
|
21 offset classes from –2.0 to +2.0 sec with 0.2-sec step size.
The metric tolerates ±1 temporal class (±0.2 sec) mistakes.
Accuracy
|
|
| AVSTdec | 83.1 | 29.3 |
| Ours | 96.9 | 44.3 |
We open-source the code and the pre-trained models GitHub. For a quick start, you may check our Google Colab Demo.
Funding for this research was provided by the Academy of Finland projects 327910 and 324346, EPSRC Programme Grant VisualAI EP/T028572/1, and a Royal Society Research Professorship. We also acknowledge CSC – IT Center for Science, Finland, for computational resources.