Dense video captioning aims to localize and describe important events in untrimmed videos. Existing methods mainly tackle this task by exploiting visual information alone, while completely neglecting the audio track.
To this end, we present Bi-modal Transformer with Proposal Generator (BMT), which efficiently utilizes audio and visual input sequences to select events in a video and, then, use these clips to generate a textual description.

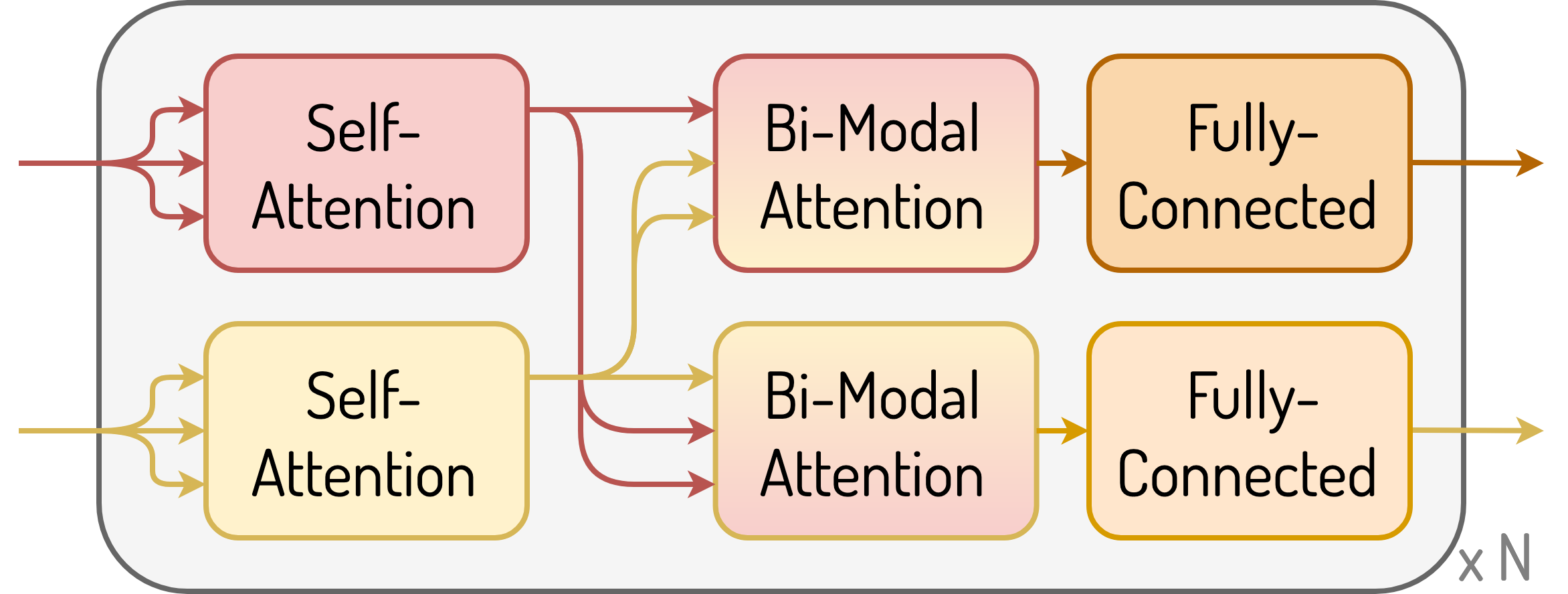
Audio and visual features are encoded with VGGish and I3D while caption tokens with GloVe. First, VGGish and I3D features are passed through the stack of N bi-modal encoder layers where audio and visual sequences are encoded to form, what we call, audio-attended visual and visual-attended audio features. These features are passed to the bi-modal multi-headed proposal generator, which generates a set of proposals using information from both modalities.
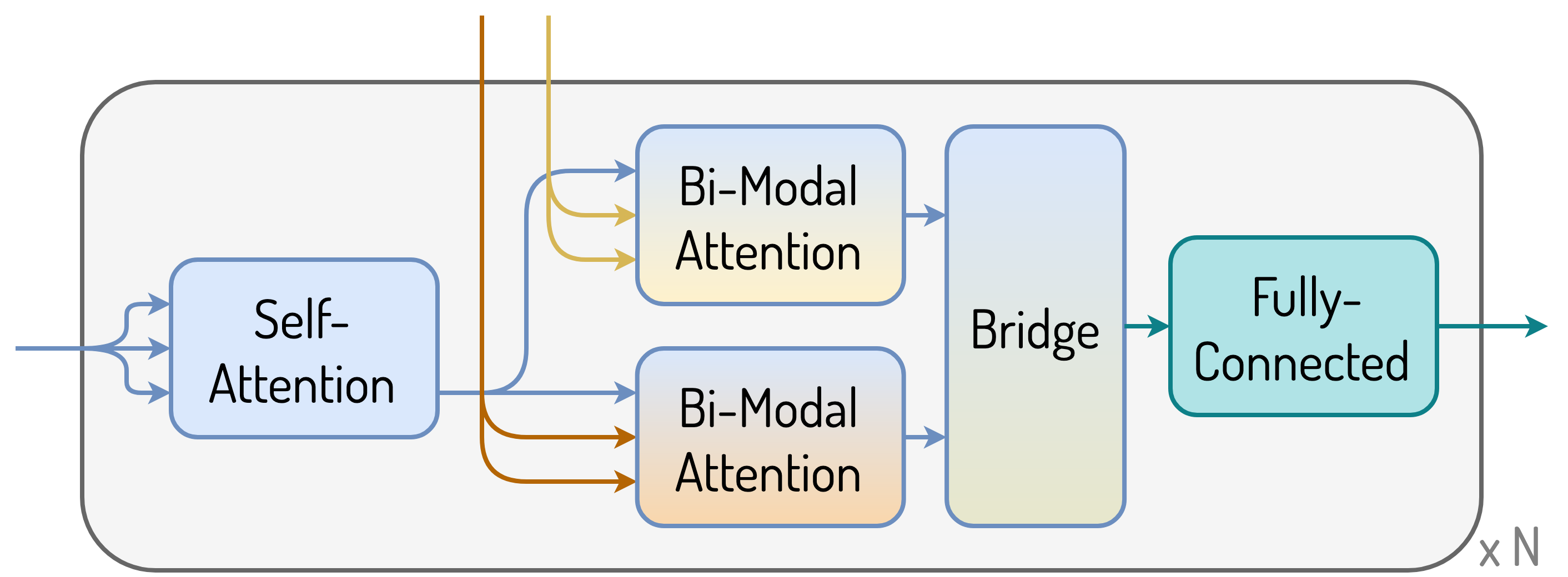
Then, the input features are trimmed according to the proposed segments and encoded in the bi-modal encoder again. The stack of N bi-modal decoder layers inputs both: a) GloVe embeddings of the previously generated caption sequence, b) the internal representation from the last layer of the encoder for both modalities. The decoder produces its internal representation which is, then, used in the generator to model the distribution over the vocabulary for the next caption word.
Next, I will introduce the essential parts of the architecture, in particular, Bi-modal Encoder, Bi-modal Decoder, and Bi-modal Proposal Generator. I will assume that you are familiar with the concepts of Transformer and YOLO.