RAFT
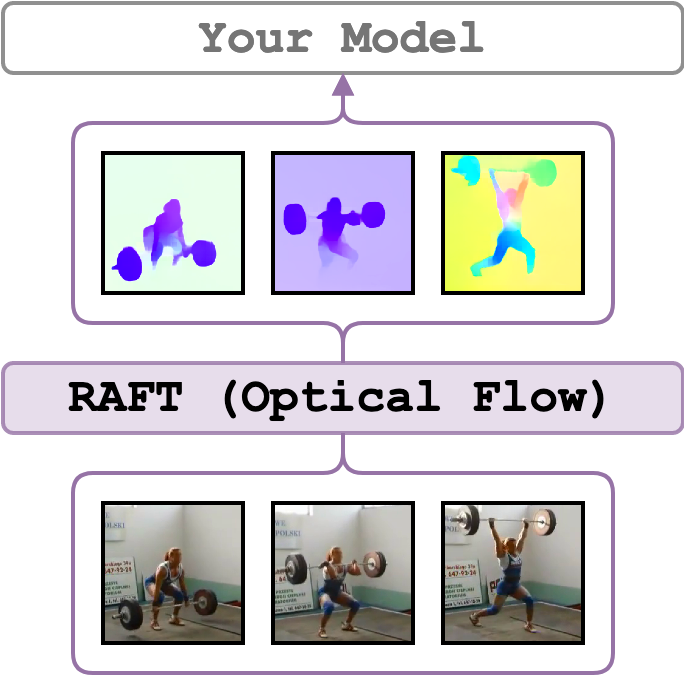
Recurrent All-Pairs Field Transforms for Optical Flow (RAFT) frames are extracted for every consecutive pair of frames in a video. The implementation follows the official implementation. RAFT is pre-trained on FlyingChairs, fine-tuned on FlyingThings3D, then it is finetuned on Sintel or KITTI-2015 (see the Training Schedule in the Experiments section in the RAFT paper). Also, check out and this issue to learn more about the shared models.
The optical flow frames have the same size as the video input or as specified by the resize arguments. We additionally output timesteps in ms for each feature and fps of the video.
Quick Start
![]()
Ensure that the environment is properly set up before proceeding. See Setup Environment for detailed instructions.
Activate the environment
and extract optical flow from ./sample/v_GGSY1Qvo990.mp4 using one GPU and show the flow for each frame
show_pred=true, the window with predictions will appear, use any key to show the next frame.
To use show_pred=true, a screen must be attached to the machine or X11 forwarding is enabled.
Supported Arguments
Argument |
Default |
Description |
|---|---|---|
finetuned_on |
sintel |
The RAFT model is pre-trained on FlyingChairs, then it is fine-tuned on FlyingThings3D, and then it is fine-tuned on finetuned_on dataset that can be either sintel or kitti. |
batch_size |
1 |
You may speed up extraction of features by increasing the batch size as much as your GPU permits. |
extraction_fps |
null |
If specified (e.g. as 5), the video will be re-encoded to the extraction_fps fps. Leave unspecified or null to skip re-encoding. |
side_size |
null |
If resized to the smaller edge (resize_to_smaller_edge=true), then min(W, H) = side_size, if to the larger: max(W, H), if null (None) no resize is performed. |
resize_to_smaller_edge |
true |
If false, the larger edge will be used to be resized to side_size. |
device |
"cuda:0" |
The device specification. It follows the PyTorch style. Use "cuda:3" for the 4th GPU on the machine or "cpu" for CPU-only. |
video_paths |
null |
A list of videos for feature extraction. E.g. "[./sample/v_ZNVhz7ctTq0.mp4, ./sample/v_GGSY1Qvo990.mp4]" or just one path "./sample/v_GGSY1Qvo990.mp4". |
file_with_video_paths |
null |
A path to a text file with video paths (one path per line). Hint: given a folder ./dataset with .mp4 files one could use: find ./dataset -name "*mp4" > ./video_paths.txt. |
on_extraction |
print |
If print, the features are printed to the terminal. If save_numpy, save_pickle, or save_h5, the features are saved to either .npy, .pkl, or .h5 file. |
output_path |
"./output" |
A path to a folder for storing the extracted features (if on_extraction is save_numpy, save_pickle, or save_h5; the latter saves to one file). |
keep_tmp_files |
false |
If true, the reencoded videos will be kept in tmp_path. |
tmp_path |
"./tmp" |
A path to a folder for storing temporal files (e.g. reencoded videos). |
show_pred |
false |
If true, the script will visualize the optical flow for each pair of RGB frames. |
Examples
Make sure the environment is set up correctly. For instructions, refer to Setup Environment.
Start by activating the environment
A minimal working example: it will extract RAFT optical flow frames for sample videos.
python main.py \
feature_type=raft \
device="cuda:0" \
video_paths="[./sample/v_ZNVhz7ctTq0.mp4, ./sample/v_GGSY1Qvo990.mp4]"
By default, the frames are extracted using the Sintel model.
If you wish you can use KITTI-pretrained model by changing the finetuned_on argument:
python main.py \
feature_type=raft \
device="cuda:0" \
finetuned_on=kitti \
video_paths="[./sample/v_ZNVhz7ctTq0.mp4, ./sample/v_GGSY1Qvo990.mp4]"
If you would like to save the frames, use --on_extraction save_numpy (or save_pickle) – by default,
the frames are saved in ./output/ or where --output_path specifies.
In the case of RAFT, besides frames, it also saves timestamps in ms and the original fps of the video into
the same folder with features.
python main.py \
feature_type=raft \
device="cuda:0" \
on_extraction=save_numpy \
video_paths="[./sample/v_ZNVhz7ctTq0.mp4, ./sample/v_GGSY1Qvo990.mp4]"
--batch_size argument (defaults to 1) to do so.
A precaution: make sure to properly test the memory impact of using a specific batch size if you are not sure which kind of videos you have. For instance, you tested the extraction on 16:9 aspect ratio videos but some videos are 16:10 which might give you a mem error. Therefore, I would recommend to tune --batch_size on a square video and using the resize arguments (showed later)
python main.py \
feature_type=raft \
device="cuda:0" \
batch_size=16 \
video_paths="[./sample/v_ZNVhz7ctTq0.mp4, ./sample/v_GGSY1Qvo990.mp4]"
resize_to_smaller_edge=true (default) if you would like --side_size to be min(W, H)
if resize_to_smaller_edge=false the --side_size value will correspond to be max(W, H) .
The latter might be useful when you are not sure which aspect ratio the videos have (the upper bound on size).
python main.py \
feature_type=raft \
device="cuda:0" \
side_size=256 \
resize_to_smaller_edge=false \
video_paths="[./sample/v_ZNVhz7ctTq0.mp4, ./sample/v_GGSY1Qvo990.mp4]"
--extraction_fps might be used to specify the target fps of all videos (a video is reencoded and saved to --tmp_path folder and deleted if --keep_tmp_files wasn't used).
python main.py \
feature_type=raft \
device="cuda:0" \
extraction_fps=1 \
video_paths="[./sample/v_ZNVhz7ctTq0.mp4, ./sample/v_GGSY1Qvo990.mp4]"
Credits
- The Official RAFT implementation (esp.
./demo.py). - The RAFT paper: RAFT: Recurrent All Pairs Field Transforms for Optical Flow.
License
The wrapping code is under MIT, but the RAFT implementation complies with BSD 3-Clause.